Examples >
Scrape HackerNews Posts

What this template contains
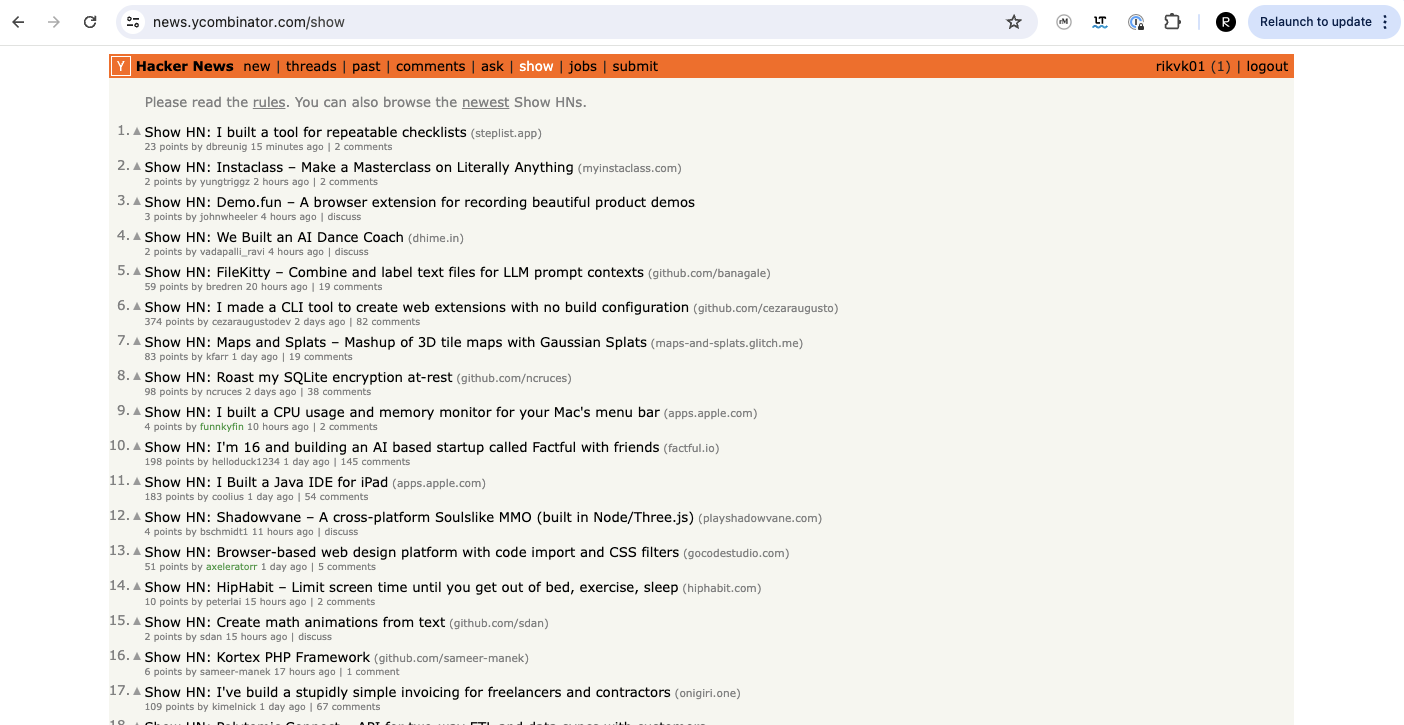
This template will show you how to scrape posts from HackerNews, so you can get the titles,
links, authors and upvotes. This strategy works both on hot or new posts.
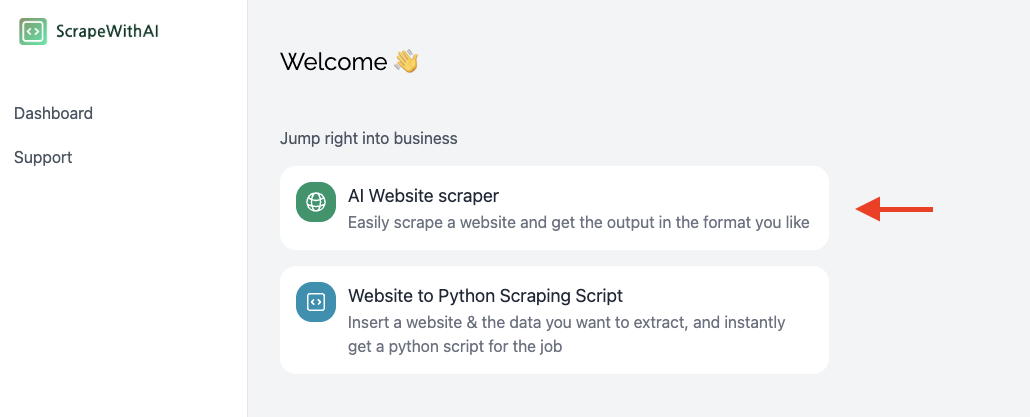
Step 1 - Open the AI Webscraper
Open your ScrapeWithAI dashboard and click on the AI webscraper
Step 2 - 🔗 Enter your target website
Enter the target website for the company where you want to get data from, for this example
we will use 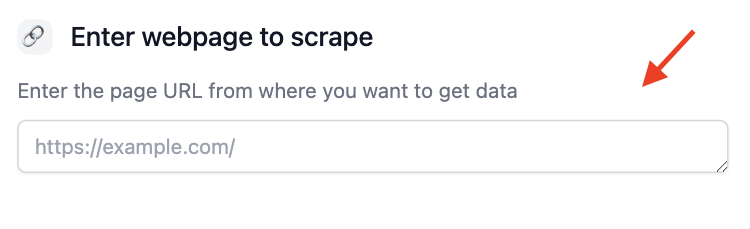 (Note: You can also use the subpages
(Note: You can also use the subpages
https://news.ycombinator.com/
(Note: You can also use the subpages
/newest, or
/show, this doesn't matter)
Step 3 - 💬 Enter your scraping instructions
For the scraping instructions, we will instruct the model to extract the contact information
we want, feel free to adapt this 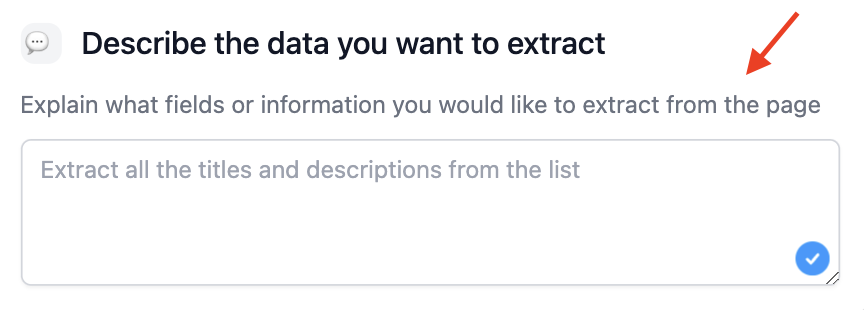
Get all the posts, get the title, author, external link (if available) and the amount of
upvotes. If link is not available, just return an empty string for that field.
Step 4 - Click "Start Scraping" and get the results!
You can select the output format you prefer and click "Start Scraping"
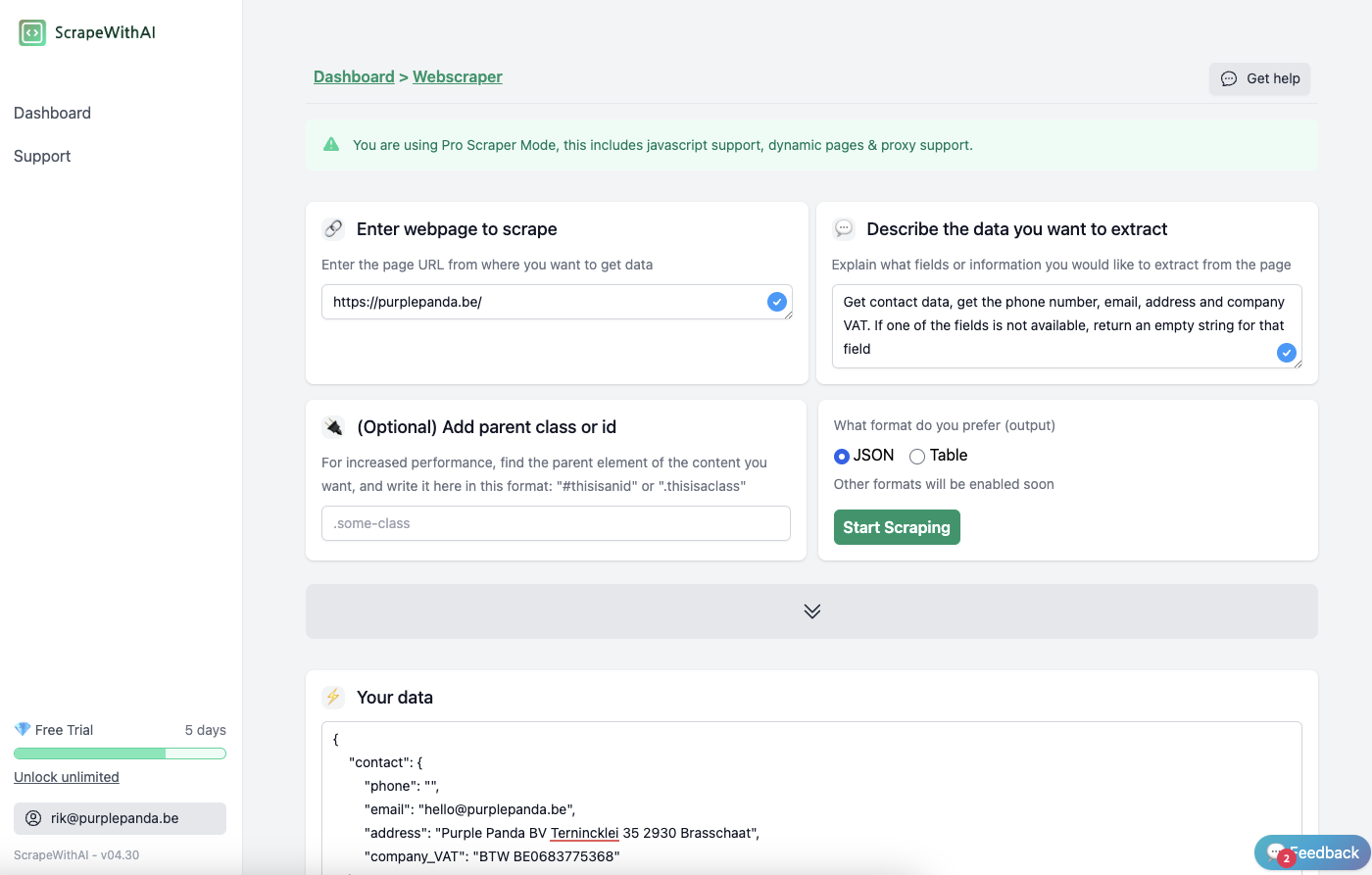
 After that, you will get the following result:
After that, you will get the following result:
After that, you will get the following result:
{
"posts": [
{
"title": "Show HN: I built a tool for repeatable checklists",
"author": "dbreunig",
"link": "https://steplist.app/",
"upvotes": 32
},
{
"title": "Johnson and Johnson announces $6.5B settlement over ovarian cancer allegations",
"author": "elsewhen",
"link": "https://www.axios.com/2024/05/01/johnson-johnson-talc-baby-powder-settlement-ovarian-cancer",
"upvotes": 55
},
...
As you can see, scraping HackerNews is pretty straightforward. Good luck!Try it for yourself!
 We have built one of the easiest platforms on the market to scrape websites. Try it out today.
We have built one of the easiest platforms on the market to scrape websites. Try it out today.